RStudioでの実行。R.4.3.3+Stools4.3を使用。
Stanコード
``{stan output.var="stan_model"}
// stanファイルを読み込まない方にするには"```{stan output.var="stan_model"} "と書く
data {
int<lower=0> N; // サンプルサイズ
int<lower=0, upper=1> X[N]; // 独立変数(性別、0: 男性、1: 女性)
real Y[N]; // 従属変数(賃金)
}
parameters {
real alpha; // 切片
real beta; // 性別の効果
real<lower=0> sigma; // 誤差の標準偏差
}
model {
vector[N] gender_effect = rep_vector(0, N); // 性別効果のベクトルを初期化
for (i in 1:N) {
gender_effect[i] = (X[i] == 1) ? 1 : 0; // 性別が1の場合は1、それ以外(つまり0)は0
}
Y ~ normal(alpha + beta * gender_effect, sigma); // 単回帰モデル
}
``
独立変数が連続変数の場合は"vector[N] X;"になるが、カテゴリカル変数の場合は"int<lower=0, upper=1> X[N];"となる。ここで、"lower=0"はXの値が0以上であることを示し、"upper=1"はXの値が1以下であることを示す。このようにすることで、Xの値が0か1のどちらかであることを明示的に示している。
AERデータgernderはfactor型で"male""female"が入っているので、integer型に変換するとよいようにも思えるが、Stanコードの中で新しい変数を作った方がStanの設計思想的にはよいようだ。modelの中身は下記のようになっている。
- 性別効果のベクトルの初期化 vector[N] gender_effect は、性別に基づく効果を格納するためのベクトルである。すべての要素を 0 で初期化する。
- 性別に基づいた効果の設定 ループ内で、X[i] の値に基づき gender_effect[i] を 1(女性)または 0(男性)に設定する。これにより、betaの効果を性別に応じて適用することができる。
- 正規分布による回帰モデル gender_effect を使用して Y の分布を定義する。Y の各値が、alpha + beta * gender_effect の線形予測子と sigma 標準偏差を持つ正規分布に従うと仮定する。
Rコード
library(rstan)
library(AER)
data("CPS1985", package = "AER")
N <- nrow(CPS1985)
X <- ifelse(CPS1985$gender == "male", 0, 1) # 男性を0、女性を1に変換
Y <- CPS1985$wage
stan_data <- list(N = N, X = X, Y = Y)
fit <- sampling(stan_model, data = stan_data, iter = 2000, chains = 4)
print(fit)
Inference for Stan model: anon_model.
4 chains, each with iter=2000; warmup=1000; thin=1;
post-warmup draws per chain=1000, total post-warmup draws=4000.
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat
alpha 10.00 0.01 0.30 9.41 9.79 9.99 10.20 10.59 2142 1
beta -2.12 0.01 0.44 -2.99 -2.41 -2.12 -1.82 -1.25 2199 1
sigma 5.05 0.00 0.15 4.76 4.94 5.04 5.15 5.36 2432 1
lp__ -1128.97 0.03 1.22 -1132.20 -1129.47 -1128.66 -1128.10 -1127.58 1810 1
Samples were drawn using NUTS(diag_e) at Mon Apr 15 01:44:33 2024.
For each parameter, n_eff is a crude measure of effective sample size,
and Rhat is the potential scale reduction factor on split chains (at
convergence, Rhat=1).
収束診断
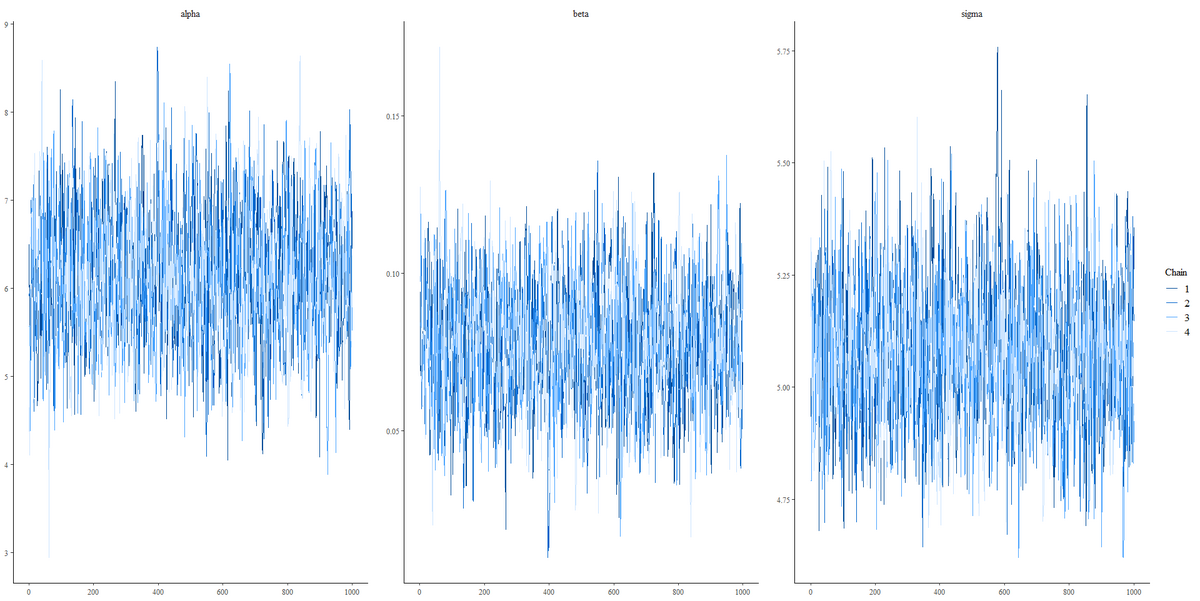
bayesplot::mcmc_trace(as.array(fit), pars = c("alpha", "beta", "sigma"))

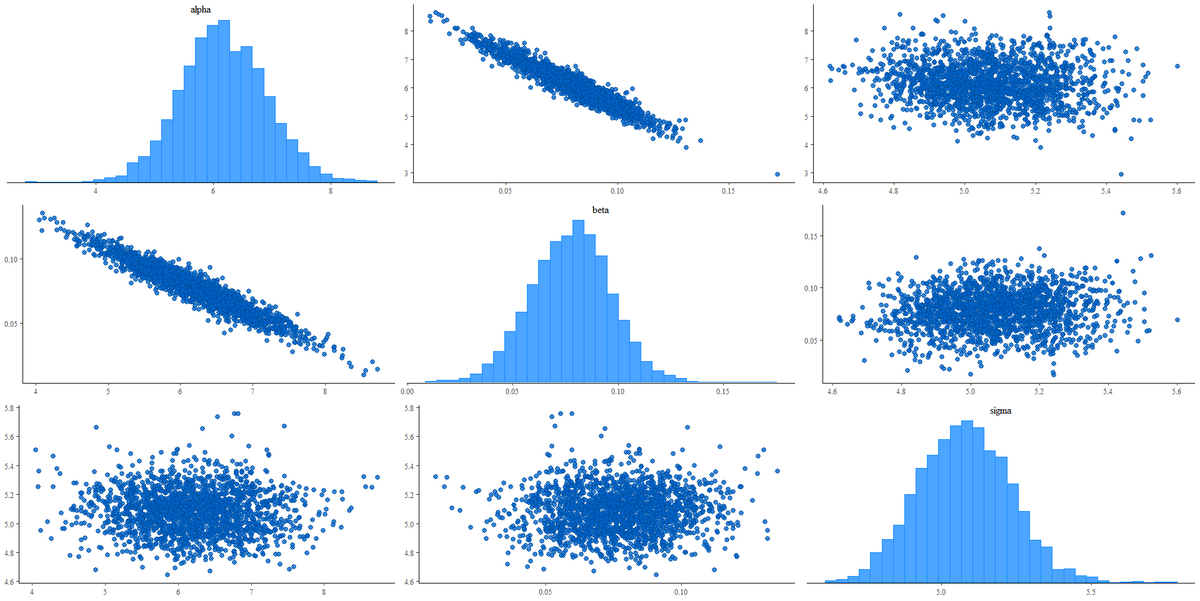
ペアプロット
bayesplot::mcmc_pairs(
as.array(fit),
pars = c("alpha", "beta", "sigma"),
off_diag_args = list(size = 0.5) # オフダイアゴナルのプロットの点の大きさ
)

1.事後分布の形状:
- 各パラメータのヒストグラムが単峰性であり、重い裾野を示さないことは良好なサンプリングを示唆している。
- alpha と sigma の分布が正規分布に近い形をしている一方で、beta は左に歪んでいる。
2.パラメータ間の相関:
- alpha と beta の間には負の相関が明らかであり、alpha の値が増加すると beta の値が減少する傾向にある。これは、これらのパラメータがモデルの中で相互に影響を及ぼしている可能性があることを意味する。
- sigma と他のパラメータ間の顕著な相関は見られないため、sigma が他のパラメータから独立して推定されていることが示唆される。
3.MCMCの収束:
- サンプルがパラメータの事後分布全体を探索していることを示すため、ペアプロットの散布図が重要である。点が全体的に均一に分布している場合は、チェーンが良好に混合しており、収束している可能性が高い。
4.異常値の検出:
- 散布図に極端な値や点の集団が見当たらないことから、異常値や非定常性が少ないと考えられる。
5.サンプリングの効率:
- パラメータ間に強い相関が見られる場合、MCMCサンプルの効率が悪くなることがある。特に alpha と beta 間の相関に注意し、モデルの再構築や再パラメータ化の必要性を検討する必要がある。
事後予測チェック
library(bayesplot)
# 事後サンプルからパラメータを抽出
posterior_samples <- extract(fit)
# 事後予測サンプルのマトリクスを生成
num_draws <- length(posterior_samples$alpha) # 事後サンプルの数
predicted_Y <- matrix(NA, nrow = num_draws, ncol = N) # 初期化
for (i in 1:num_draws) {
predicted_Y[i, ] <- rnorm(
N,
mean = posterior_samples$alpha[i] + posterior_samples$beta[i] * X,
sd = posterior_samples$sigma[i]
)
}
# 事後予測チェック
ppc_check <- bayesplot::pp_check(object = Y, yrep = predicted_Y, fun="dens_overlay")
print(ppc_check)

実効サンプルサイズ
fit_summary <- monitor(fit) print(fit_summary)
パラメータ推定値
Inference for the input samples (4 chains: each with iter = 2000; warmup = 0):
Q5 Q50 Q95 Mean SD Rhat Bulk_ESS Tail_ESS
alpha 9.5 10.0 10.5 10.0 0.3 1 2664 2375
beta -2.8 -2.1 -1.4 -2.1 0.4 1 2667 2810
sigma 4.8 5.0 5.3 5.0 0.2 1 2710 2770
lp__ -1131.3 -1128.6 -1127.6 -1128.9 1.2 1 1984 2547
alpha (切片): 平均約10.0で、95%の事後予測区間はおおよそ9.5から10.5。 beta (性別の効果): 平均約-2.1で、性別が女性の場合に賃金が平均で2.1単位低くなることを示す。95%の事後予測区間は約-2.8から-1.4。 sigma (誤差の標準偏差): 平均約5.0で、95%の事後予測区間はおおよそ4.8から5.3。
収束診断
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat valid Q5
alpha 9.996004 0.005561523 0.2871481 9.419926 9.800500 9.998778 10.189074 10.563379 2655 1.0003546 1 9.524529
beta -2.121264 0.008184560 0.4224828 -2.955459 -2.398296 -2.125875 -1.838553 -1.280030 2653 1.0005527 1 -2.815971
sigma 5.048379 0.002941759 0.1527884 4.756829 4.940429 5.044671 5.150279 5.355369 2666 1.0027481 1 4.806732
lp__ -1128.933244 0.026932330 1.1854162 -1131.987319 -1129.477722 -1128.627958 -1128.058523 -1127.571767 1931 0.9996243 1 -1131.253235
Q50 Q95 MCSE_Q2.5 MCSE_Q25 MCSE_Q50 MCSE_Q75 MCSE_Q97.5 MCSE_SD Bulk_ESS Tail_ESS
alpha 9.998778 10.46963 0.020787938 0.006931741 0.006684017 0.006216060 0.011640883 0.003933021 2664 2375
beta -2.125875 -1.42042 0.023410292 0.011065249 0.009017414 0.011599195 0.013583417 0.005787992 2667 2810
sigma 5.044671 5.30261 0.007056154 0.003346517 0.004070424 0.005350249 0.007428899 0.002083929 2710 2770
lp__ -1128.627958 -1127.62371 0.124659741 0.042550946 0.023439357 0.020565164 0.005784556 0.019046901 1984 2547
Rhat: 各パラメータの Rhat 値は1.00に非常に近く、これはMCMCチェーンがうまく収束していることを示す。Rhat値が1.05以下であれば、通常、収束しているとみなされる。
Bulk_ESS と Tail_ESS: Bulk_ESS は、事後分布の「大部分」に対する有効サンプルサイズで、Tail_ESSは事後分布の「裾」に対する有効サンプルサイズである。どちらもパラメータによっては2000以上(サンプル数2000の4チェーンであれば8000サンプルのうち約2000以上が有効)と高く、これはサンプルが十分に独立しており、推定が信頼できることを示唆している。
RとStanでの感度分析
``{stan output.var="sensitivity_analysis"}
data {
int<lower=0> N; // サンプルサイズ
int<lower=0, upper=1> X[N]; // 独立変数(性別、0: 男性、1: 女性)
real Y[N]; // 従属変数(賃金)
}
parameters {
real alpha; // 切片
real beta; // 性別の効果
real<lower=0> sigma; // 誤差の標準偏差
}
model {
// 変更した事前分布
alpha ~ normal(0, 10); // 広範囲の事前分布
beta ~ normal(0, 5); // 広範囲の事前分布
sigma ~ cauchy(0, 2); // 厳しい事前分布
vector[N] gender_effect = rep_vector(0, N);
for (i in 1:N) {
gender_effect[i] = (X[i] == 1) ? 1 : 0;
}
Y ~ normal(alpha + beta * gender_effect, sigma);
}
library(rstan)
library(AER)
# CPS1985データセットの読み込み
data("CPS1985", package = "AER")
# データの準備
N <- nrow(CPS1985)
X <- ifelse(CPS1985$gender == "male", 0, 1)
Y <- CPS1985$wage
# Stanデータリストの作成
stan_data <- list(N = N, X = X, Y = Y)
# 新しいStanモデルのフィッティング
fit_sensitivity <- sampling(sensitivity_analysis, data = stan_data, iter = 2000, chains = 4)
# モデルの結果をプリント
print(fit_sensitivity)
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat alpha 9.98 0.01 0.29 9.41 9.78 9.98 10.17 10.53 2301 1 beta -2.09 0.01 0.44 -2.93 -2.39 -2.09 -1.80 -1.24 2230 1 sigma 5.04 0.00 0.16 4.74 4.94 5.04 5.14 5.36 2596 1 lp__ -1131.54 0.03 1.21 -1134.72 -1132.11 -1131.25 -1130.67 -1130.16 1754 1
1. パラメータの事後分布の変化
alpha(切片):
平均値は元のモデルが10.00、感度分析モデルが9.98とほぼ変わらない。
標準偏差は0.30から0.29へわずかに減少している。
事後分布の幅(2.5%から97.5%)も若干縮小している。
beta(性別の効果):
平均値は-2.12から-2.09へわずかに増加している。
標準偏差と事後分布の幅に大きな変化は見られない。
sigma(誤差の標準偏差):
平均値と標準偏差に顕著な変化はない。
事後分布の幅にも大きな変化は見られない。
2. 収束診断(Rhat)
Rhatはどちらのモデルも1に非常に近く、チェーンが適切に収束していることを示している。Rhatが1.05以下である場合、MCMCサンプルが十分に収束していると見なされる。
3. 実効サンプルサイズ(n_eff)
実効サンプルサイズは、感度分析モデルでわずかに増加している場合があり、サンプルが異なる事前分布の影響を受け、異なる挙動を示していることを意味するが、全体的な影響は限定的である。
判断基準
パラメータの推定値が大幅に変わらない場合、モデルは事前分布の選択に対してロバストであると言える。この場合、alpha、beta、sigmaの事後推定値が元のモデルと感度分析モデルで類似しているため、モデルの推定値は事前分布の変更に対してあまり敏感ではないと解釈できる。
収束診断と実効サンプルサイズが適切であることも、MCMCサンプルが信頼できることを示している。