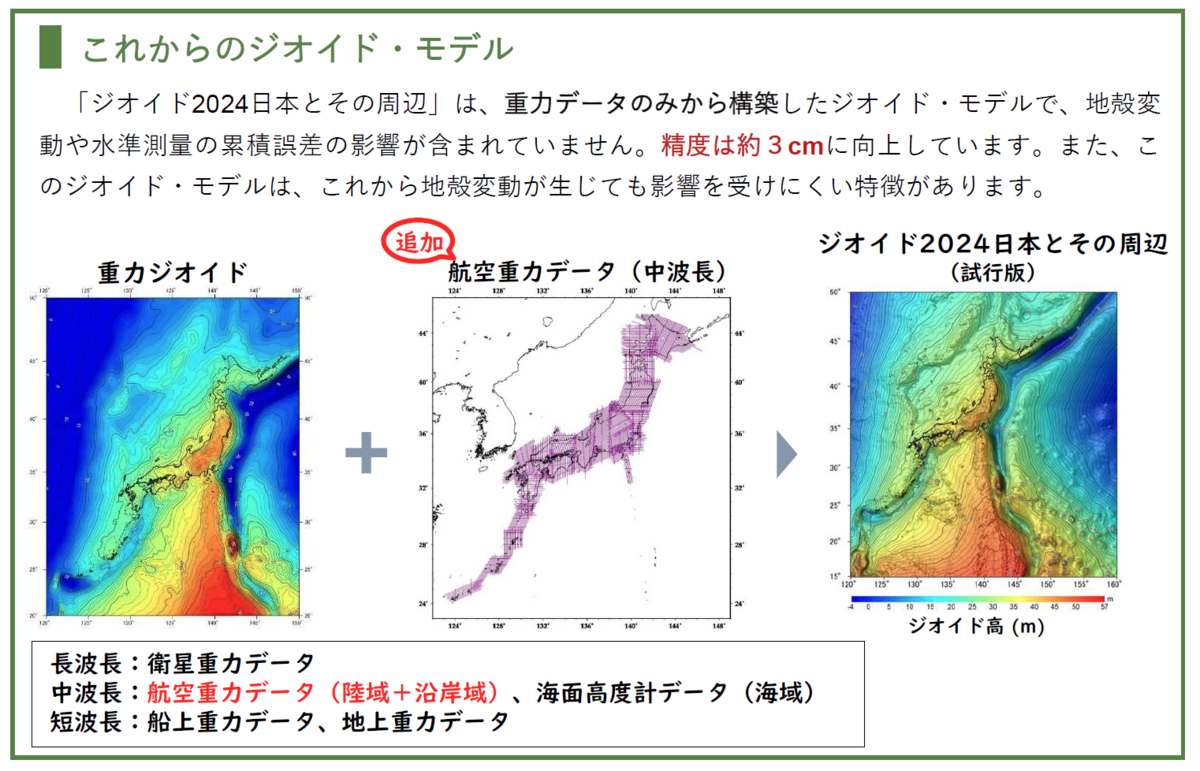
発端
ふと、「IS NOT DISTINCT FROM」あるいは「IS DISTINCT FROM」という文字列が含まれるSQL文を目にしました。
SQLの基本的な構文として、
SELECT DISTINCT col1, col2 FROM t1;
とか書くので、そのDISTINCT と FROM が、、、、とか考えていると混乱します。とりあえず「単にこういう長い名前の記号」と思っておくのがよさそう(笑)。
これはなに
https://t.co/XofaCJumh8
— Hiroshi Sekiguchi 🍥 (@discus_hamburg) 2024年4月22日
これですよね?
Oracleから入り、その後MySQLをメインとするようになった私の通った道には、こんな構文はなかったわけです。それにしても、SQLiteでさえ(←ひどい言い草)対応しているのにMySQLにないってのは、ちょっと悔しい(笑)。
PostgreSQL 16 で動作を確認
こんなデータを作った。
\pset null (null) create table t1 (id integer, s varchar(10)); SELECT * FROM t1; id | s ----+-------- 1 | AA 2 | CBB 3 | AA 4 | CC 5 | 6 | CC 7 | 8 | (null) 9 | (null) (9 rows)
単純に結合するとこんな感じ(自分自身との結合を除外)。
db=# SELECT ta.*, tb.* FROM t1 ta, t1 tb WHERE ta.id<>tb.id; id | s | id | s ----+-----+----+----- 2 | CBB | 1 | AA 3 | AA | 1 | AA 4 | CC | 1 | AA : 5 | | 9 | 6 | CC | 9 | 7 | | 9 | 8 | | 9 | (72 rows)
値が同じのだけを抽出したい場合は、(今までの私の発想だと)イコールを使う。ここに null のものは現れない。
db=# SELECT ta.*, tb.* FROM t1 ta, t1 tb WHERE ta.s = tb.s AND ta.id<>tb.id; id | s | id | s ----+----+----+---- 1 | AA | 3 | AA 4 | CC | 6 | CC 5 | | 7 | 3 | AA | 1 | AA 6 | CC | 4 | CC 7 | | 5 | (6 rows)
IS NOT DISTINCT FROM を使うと、nullも「nullという値だとみなして」一致比較をしてくれる。「nullという値」というとっても気持ち悪いパワーワードですが「みなして」ということで我慢することにします:-)
db=# SELECT ta.*, tb.* FROM t1 ta, t1 tb WHERE ta.s IS NOT DISTINCT FROM tb.s AND ta.id<>tb.id; id | s | id | s ----+--------+----+-------- 3 | AA | 1 | AA 1 | AA | 3 | AA 6 | CC | 4 | CC 7 | | 5 | 4 | CC | 6 | CC 5 | | 7 | 9 | (null) | 8 | (null) 8 | (null) | 9 | (null) (8 rows)
余談
本題ではないのだけど、今回試したクエリで、行きと帰りの一致データが重複して出ているのが気になりますよね。
今回は「IDが一致しないもの」ということで自分自身との結合を除外しましたが、この条件を「IDが自分よりも小さいもの」とだけ比較するようにすると片道切符になります。
db=# SELECT ta.*, tb.* FROM t1 ta, t1 tb WHERE ta.s IS NOT DISTINCT FROM tb.s AND ta.id<tb.id; id | s | id | s ----+--------+----+-------- 1 | AA | 3 | AA 4 | CC | 6 | CC 5 | | 7 | 8 | (null) | 9 | (null) (4 rows)
最初からこちらでやっていたほうが、結果がシンプルになりましたね。
応用例
IS NOT DISTINCT FROM ではなく IS DISTINCT FROM を使うと、不一致のものにマッチさせることができます。
たとえば、値が'AA'のものと、これに一致しないもののIDの対応表を作りたい時に、こんなふうに。
対象としてnullも含まれるところが、新しいところです(べつに新しくないのですが、= とか <> しか知らなかった私には新しい)。
db=# SELECT ta.*, tb.* FROM t1 ta, t1 tb WHERE ta.s='AA' AND ta.s IS DISTINCT FROM tb.s AND ta.id<tb.id; id | s | id | s ----+----+----+-------- 1 | AA | 2 | CBB 1 | AA | 4 | CC 1 | AA | 5 | 1 | AA | 6 | CC 1 | AA | 7 | 1 | AA | 8 | (null) 1 | AA | 9 | (null) 3 | AA | 4 | CC 3 | AA | 5 | 3 | AA | 6 | CC 3 | AA | 7 | 3 | AA | 8 | (null) 3 | AA | 9 | (null) (13 rows)
まとめ
今回の構文が長いので IS DISTINCT FROM を [コレ] と書くとすると、
A [コレ] B は、AがBと違っているときに成立(true)、
A NOT[コレ] B は、AがBと違ってないとき(笑)、、、つまり同じ時ですね、、に成立。(正確にはNOTの位置は IS NOT の場所になります)
既にSQL構文の中で使われている DISTINCT とか FROM という単語をこういう形でまったく違う用途で使うのって、仕様決めた人はセンスないよなと私は思ってしまうのですが、たぶん私など理解不能なレベルで考えぬいた末に、きっとセンスの塊の成果として決まったものだと思います(思いたい)。
軽く調べてみたのですが、 SQL-92には含まれていなくて、SQL-1999で登場した記法のようです。
近年のMySQL開発はどんどん、なるべく標準に準拠するようにとうことを心がけているように見えるので、そのうちこの構文が導入されたりするのかな。新機能好きなので楽しみに待ちたいと思います。導入されたら「知ってる!知ってる!導入前から注目していたんですよ!」と自慢できるように、このエントリを書いておきました(そんなわけじゃないw)。
参照
Twitter(X)で色々おしえてもらいました。ありがとうございました!
NOT がついてるのに一致すると TRUE を返すというのでいつも混乱してます。
— とみたまさひろ🍣🍺 (@tmtms) 2024年4月22日
NULL を普通の値のように比較できる感じですね。
— とみたまさひろ🍣🍺 (@tmtms) 2024年4月24日
NULL IS NOT DISTINCT FROM NULL が TRUE になる感じ。
自分が「マニュアルしか読まない」極端な育ち方をしたのはDBコミュニティのおかげ(というかほぼ @sakaik さんのおかげ( ´艸`)
— Kosuke Kida (@kkkida_twtr) 2024年4月24日
そしてちゃんと解説してる #PostgreSQL や #Snowflake のマニュアルのおかげ。マイナー構文みると嬉々として探しちゃうhttps://t.co/HtKi1DFJJOhttps://t.co/p2clOYt5ln https://t.co/Lwla0khBsv
ここ一年で検索したSQLレア構文はSnowflakeに全敗してる。こんなの絶対おかしいよ(ほめてる)
— Kosuke Kida (@kkkida_twtr) 2024年4月24日
他製品で謎SQLに出くわしたらSnowflakeのマニュアルできっと解説されてるので腹落ちしてからそっちの製品に戻るとめちゃ捗るよ#SnowflakeDB
Snowflakeのマニュアル、わかりやすい。
https://docs.snowflake.com/ja/sql-reference/functions/is-distinct-from
追記
要するにこういうことなのか。
何か新しい事ができるようになったというよりは、一種のシンタックスシュガーと捉えても良いのかな。
(ここで「絶対に既存のデータと被らない置換文字列」を決める部分で「絶対」を保証できないので、IS DISTINCT FROM の存在意義が出てくるわけですが)
db=# SELECT ta.*, tb.* FROM t1 ta, t1 tb WHERE COALESCE(ta.s,'*+;:')=COALESCE(tb.s,'*+;:') AND ta.id<tb.id; id | s | id | s ----+--------+----+-------- 1 | AA | 3 | AA 4 | CC | 6 | CC 5 | | 7 | 8 | (null) | 9 | (null) (4 rows)
db=# SELECT ta.*, tb.* FROM t1 ta, t1 tb WHERE ta.s=tb.s AND ta.id<tb.id; id | s | id | s ----+----+----+---- 1 | AA | 3 | AA 4 | CC | 6 | CC 5 | | 7 | (3 rows)
db=# SELECT ta.*, tb.* FROM t1 ta, t1 tb WHERE ta.s IS NOT DISTINCT FROM tb.s AND ta.id<tb.id; id | s | id | s ----+--------+----+-------- 1 | AA | 3 | AA 4 | CC | 6 | CC 5 | | 7 | 8 | (null) | 9 | (null) (4 rows)