Don’t trust. Verify.

Here follows a brief description on how you can detect if the curl package would ever make an xz.
xz (and its library liblzma) was presumably selected as a target because it is an often used component and by extension via systemd it often used by openssh in several Linux distros. libcurl is probably an even more widely used software component and if infected, could potentially serve as an effective vessel to distribute evil into the world.
Conceivably, the xz attackers have infiltrated more than one other Open Source project to cover their bases. Which ones?
No inexplicable binary blobs
First, you can verify that there are no binary blobs stored in git that could host an encrypted attack payload, planted there for the future.
Every file in the curl git repository has a benign meaning and purpose. As part of the products, the documentation, tooling or the test suites etc.
Without any secret “hide-out” in the git repository, you know that any backdoor needs to be provided either in plain code or using some crazy weird steganography. Or get inserted into the tarballs with content not present in git – read on for how to verify that this is not happening.
No disabled fuzzers
The xz attack could have been detected by proper fuzzing (and valgrind use) which is why the attacker made sure to sneakily disable such automated checks of code.
While somewhat hard to verify, you can make sure that no such activities have been done in curl’s fuzzing or curl’s automated and CI testing,
No hidden payloads in tarballs
In the curl project we generate several files as part of the release process and those files end up in the release tarball. This means that not all files in the tarball are found in the git repository. (Because we don’t commit generated files.)
The generated files are produced with a small set of tools, and these tools use the source code available in git at the release tag. Anyone can check out the same code from that same release tag, make sure to have the corresponding tools (and versions) installed and then generate a version of the tarball themselves – to verify that this tarball indeed becomes an identical copy of the public release.
That process verifies that the tarballs we ship are generated only with legitimate tools and that the release contents originate only from the files present in git. No secret sauce added in the process. No malicious code can get inserted.
Reproducible tarballs
We have recently improved reproducibility as a direct result of the post xz-attack debate. To make sure that a repeated tarball creation actually produces the exact same results, but also to make it easier for others to verify our release tarballs. With more documentation (releases now contain documentation of exactly which tools and versions that generated the tarball) and by making it easier to run the exact same virtual machine and tool setup like the one that created the release. We aim to soon provide a Dockerfile to make this process even smoother.
We also verify tarball reproducibility in a CI job: generating a release tarball with a given timestamp produces the identical binary output when done again for the same timestamp.
Signed tarballs
As an extra detail, everyone can also verify that the released tarballs are in fact shipped by me Daniel personally, as they are always signed with my GPG key as part of the release process. This should at least prove that new releases are made with the same keys as previous ones were, which should with a reasonable probability be me.
The signatures also help verify that the tarballs have not been tampered with in transition, from the point I generated them to the moment they land in your download directory. curl downloads are normally distributed via a third-party CDN which we normally trust of course, but if it would ever be breached or similar, a modified tarball would be detected when the digital signature is verified.
We do not provide checksums for the tarballs simply because providing checksums next to the downloads adds almost no extra verification. If someone can tamper with the tarballs, they can probably update the webpage with a fake checksum as well.
Signed commits
All commits done to curl done by me are signed, You can verify that I did them. Not all committers in the project do them signed, unfortunately. We hope to increase the share going forward. Over the last 365 days, 73% of the curl commits were signed.
These signatures only verify that the commits where done by a maintainer of the curl project (or someone who controls that account). A maintainer you may not trust and who might not be known under their real name and you do not even know in which country they live. And of course, even a trusted maintainer can suddenly go rogue.
Is the content in git benign?
The process above only verifies that tarballs are indeed generated (only) from contents present in git and that they are unaltered from the moment I made them.
How do you know that the contents in git does not contain any backdoors or other vulnerabilities?
Without trusting anyone else’s opinions and without just relying on the fact that you can run the test suite, fuzzers and static code analyzers without finding anything, you can review it. Or pay someone else to review it.
We have had curl audited several times by external organizations, but can you trust claimed random audits?
Anonymous contributors
We regularly accept contributions from anonymous and pseudonymous contributors in curl – and we always have. Our policy says that if a contribution is good: if it passes review and all tests run green, we have no reason to deny it – in the name of progress and improvement. That is also why we accept even single-letter typo fixes: even a very small fix is a step in the right direction.
A (to me) surprisingly large amount of contributions are done by people who do not state a full real name. They may chose to be anonymous for various reasons – we do not ask. Maybe they fear retaliation if they would propose something that ends up buggy? Sometimes people want to hide their affiliation/origin so that their contribution is not associated with the organization they work at. Another reason sometimes mentioned is that women do it to avoid revealing themselves as female. etc. As I said: we do not ask so I cannot tell for sure.
Anonymous maintainers
We do not have anonymous maintainers, but we don’t actually have rules against it.
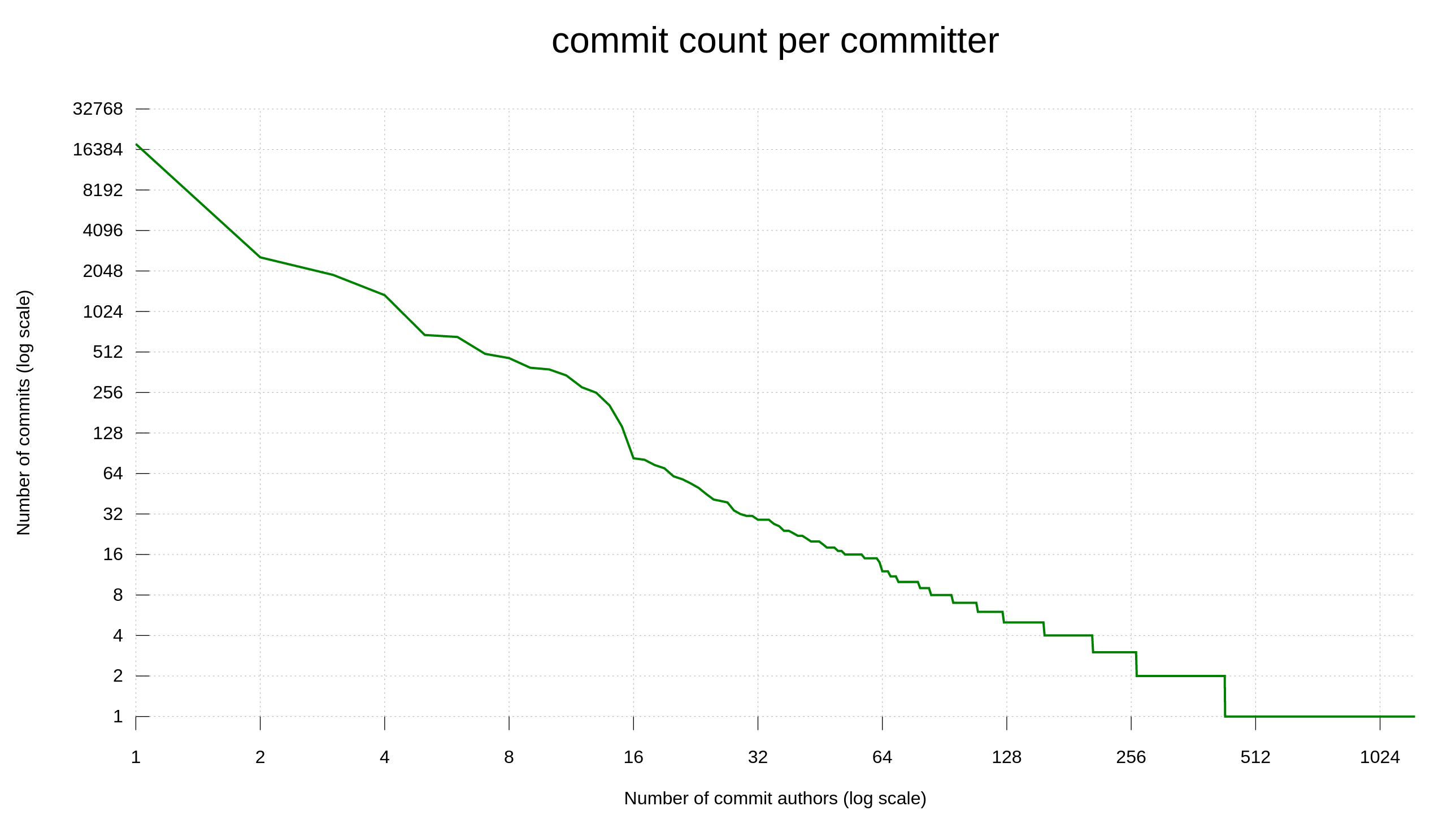
Right now, we have 18 members in the GitHub curl organization with the rights to push commits. I have not met all of them. I have not even seen the faces of all of them. They have all proven themselves worthy of their administrative rights based on their track record. I cannot know if anyone of them is using a false identity and I do not ask nor keep track in which country they reside. A former top maintainer in the curl projected even landed a large amount of changes under a presumed/false name during several years.
If a curl maintainer suddenly goes rogue and attempts to land malicious content, our only effective remedy is review. To rely on the curl community to have eyes on the changes and to test things.
Can curl be targeted?
I think it would be very hard but I can of course not rule it out. Possibly I am also blind for our weaknesses because I have lived with them for so long.
Everyone can help the greater ecosystem by verifying a package or two. If we all tighten all screws just a little bit more, things will get better.
Vulnerabilities
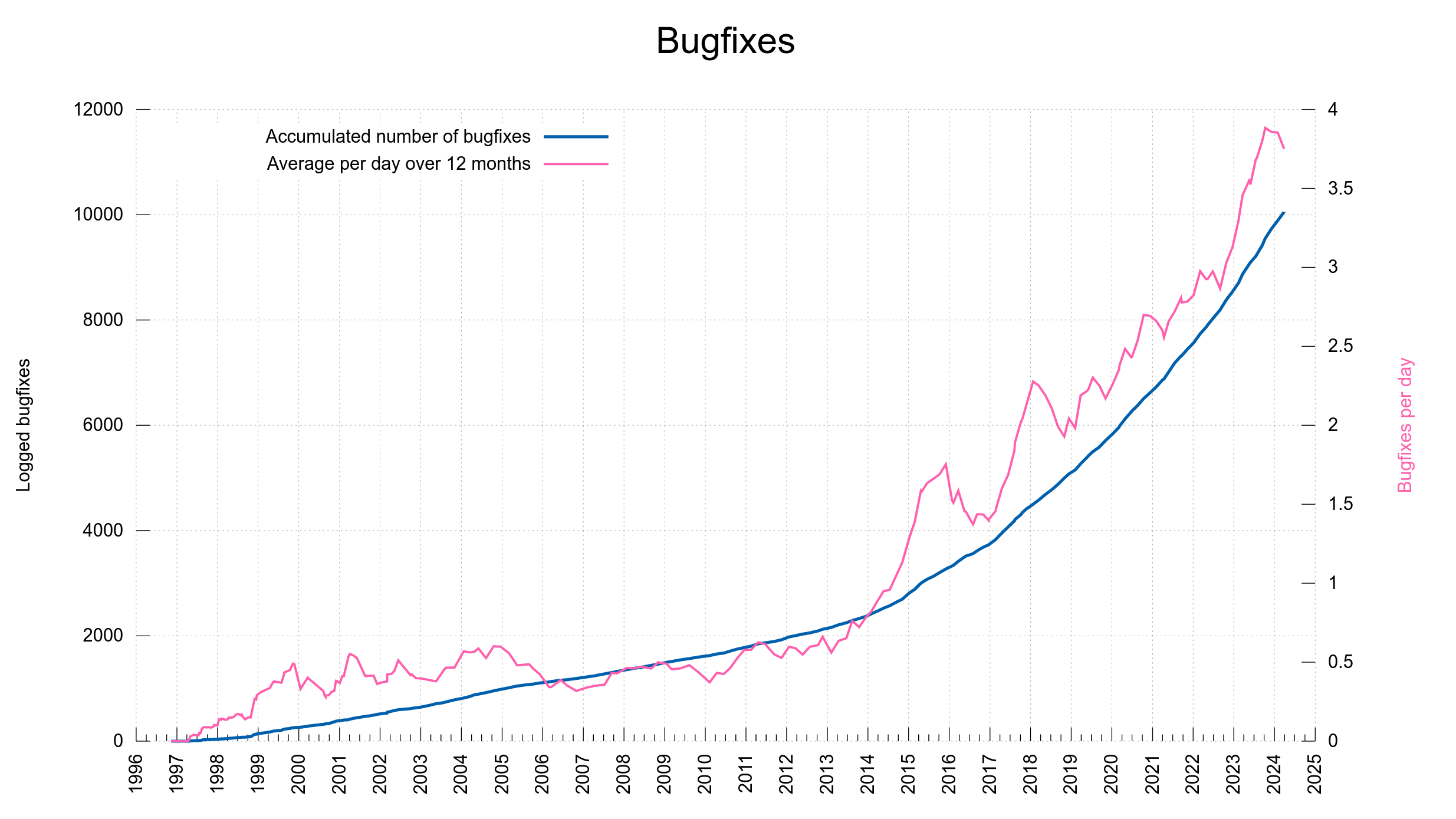
I maintain that planting a backdoor in curl code is so infuriatingly hard to achieve that efforts and energy are probably much rather spent on finding security vulnerabilities and ways to exploit them. After all, we have 155 published past vulnerabilities in curl so far, out of which 42 have been at severity high or critical.
I can be fairly sure that none of those 42 somewhat serious issues were deliberately planted, because just about every one of them were found in code that I personally authored…
People often ask. But I have never seen a backdoor attempt in curl. Maybe that is just me being naive.
Credits
Top Image by Gerd Altmann from Pixabay. Fake book cover by Daniel Stenberg.