eneloopを4本用意してXC9306使用同期整流昇降圧DC/DCコンバータ[1]を噛まして3.3VにしてESP32-WROOM-32E開発ボード[2]にツッコんでみた。電池の電圧を測りつつ、その値をWiFi経由で5秒に1回udpパケットとしてサーバーに送るプログラムを書いて、どれだけ時間的にもつのか試してみた。
分かったことは2つ
- 48時間は持たないけど、36時間ぐらいなら持つ
- eneloopの電池の持ち方の特性は説明通りだった
5秒に一度128バイト程度のデータを送り続けるわけで、それで40時間ぐらいは持っているので、悪くはないというか、データシート[3]から想定される値と大きく違いはなかった。
eneloop[4]も一定の期間安定していて、最後にストンと落ちるニッケル水素電池の特性をきちんと示していた[fig1]。
つけっぱなしでも一日ぐらいは余裕で持つというということがわかった。
[1] XC9306使用同期整流昇降圧DC/DCコンバータ
https://akizukidenshi.com/catalog/g/g116055/
[2] ESP32-DevKitC-32E ESP32-WROOM-32E開発ボード 4MB
https://akizukidenshi.com/catalog/g/g115673/
[3] ESP32-WROOM-32E & ESP32-WROOM-32UE Datasheet
https://akizukidenshi.com/goodsaffix/esp32-wroom-32e_esp32-wroom-32ue_datasheet_en.pdf
[4] エネループ(ニッケル水素電池)
https://panasonic.jp/battery/products/charge/eneloop.html
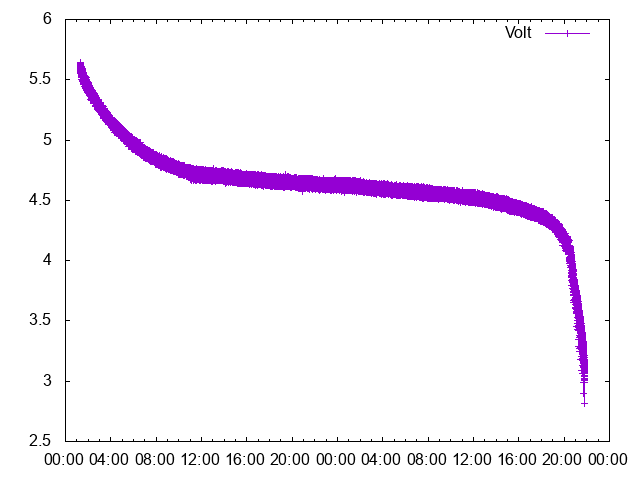
電池4本の電力変化グラフ (Fig1)