Geoguessrで強くなりたかった(最近やってないが)のと、あとラテンアメリカ文学が好きで読んでたことがあったのと、ほかにもいろいろタイミングがあって、去年からスペイン語の勉強をはじめていた。途中のマイルストーンとしてDELE A1に合格したので記録。
勉強しはじめたときにはこういう試験資格はまったくイメージしていなかったものの、勉強が中だるみしていたころにいい目標に据えられそうだったので活用した。DELEとは「Diplomas de Español como Lengua Extranjera」つまり「外国語としてのスペイン語検定」。日本でもいくつかの都市で半年に一度受ける機会がある。
この「A1」というのは初級以前の入門レベルで、CEFR(Common European Framework of Reference for Language)というヨーロッパで使われている言語の共通基準に則ったもの。馴染み深い英検でいうと3級くらいとのこと。中学卒業程度。
終わってみると大したことはないのだけど、受ける前はいろいろ分からなくてめちゃくちゃ調べることになったので、体験をまとめておく。
試験内容
試験内容は読解、聴解、会話、作文の4つということで、いちばん簡単なレベルでも会話があるというので緊張感がある。しかも読解+作文、聴解+会話それぞれのセクションで合格点を取らないと検定としては合格にならないということで、とりあえず鉛筆だけでなんとか凌ぐ! みたいなネクラ向けの作戦は取れない。問題を見てみても日常生活を意識したものが多く、実用を意識していると思う。スペイン移住の条件にA2が必要とされてもいるらしい。
会話はA1なら自己紹介と、試験官からの質問に答える+自分から質問するパート。A1レベルなら話す内容のバリエーションは多くないので、自宅で素振りしていればなんとかなると思う。テーマ(家・趣味・仕事または学校とか)が2つ提示されるうちの1つを選んで10分準備タイムがある、というのは参考書で知っていたけど、テーマは即座に選ばないといけないし準備タイムではスマホは使えない、というのは知らなかったのでだいぶ慌てた。自宅の素振りにはChatGPTアプリが音声に対応してたので使ってみたけど、とりあえず発話の練習になったくらいで自分のレベルでは会話は無理だった。
当日は10分の会話のために朝9時に会場におもむいたあと、午後の試験まで4時間ほどヒマな時間が発生することになった。周囲は学生ばかりだった中、順番が隣だった中年の方々と喫茶店に入って一緒に勉強するという不思議な時間を過ごせた。
勉強方法
よしスペイン語やろう! と思ってもいったいどこから始めたらいいのかわからないのが無学者。右往左往した結果、前に聞いたことのあったDuolingoで始めたのがよかった。Duolingoはペースがのろいなどと言われることもあると思うが、導入として選んで間違いない選択肢だと思った。結局いまも続けていてもうすぐ1年くらい。
ある程度文法が理解できてからは進度を早めるために参考書を買った。当然ながら読んで終わりではなくちゃんと手を動かして章末問題を解くのが大事。DELE A1レベルだと動詞は現在形までわかっていればなんとかなる(そう明言されているわけではないが、実際そう)ので、線過去点過去など登場してややこしくなってきたあたりで学習は失速している……。
あとは定番のAnkiでひたすら単語を覚えていった。コミュニティが共有しているデッキがあるのでよさそうなのを1つ選んでちまちま覚えていった。これで単語数を増やせるのはインスタントな進歩を感じられるので悪くない。悪い習慣として衝動的にスマホでTwitterを見たりはてブを見たりしまうので、その罪悪感を減らすためにスマホを開いたらAnkiをやる、みたいな俺ルールを課していたりもした。
あとコンテンツを楽しむのが大事~とか言われがちだけど、自分はドラマ見ないしVTuberも早口すぎて何言ってるかわからないし(あとDiscordに流れてきたミームに反応! みたいなコンテンツが多めで何言ってるか分かっても面白くないと思う)であまり続いているものはない。唯一DuolingoのSpanish Podcastは聞く価値あるな、と思って寝しなに聞いていた。これ英語の勉強にもなりそう。
第N外国語、真面目にやってみるとおもしろい
大学でやった第二外国語は中国語だったので、動詞がこんなに変化(単複・人称・過去未来・直説仮定云々)するのははじめてで最初面食らったけど、慣れてくるとちゃんとそこに規則がちゃんと見えてくる(気がする)。逆に英語が変な言語だということがよくわかる。そもそも語源が古英語・フランス語・ラテン語と3つあるとか。スペイン語の単語もどうせ英語と似てるんでしょ、と高をくくっていたけどぜんぜん一貫性がなくて意外だった。三単現だけ-sがつくのも今となっては全部変化させろやと思う。よく言われるけど発音もアクセントの位置も不定だし。
みたいな話を『英語の「なぜ?」に答える はじめての英語史』で読んで面白かった。この本はコンパニオンサイトも無料で読めるくせにかなり重厚で大変おすすめです。
結果
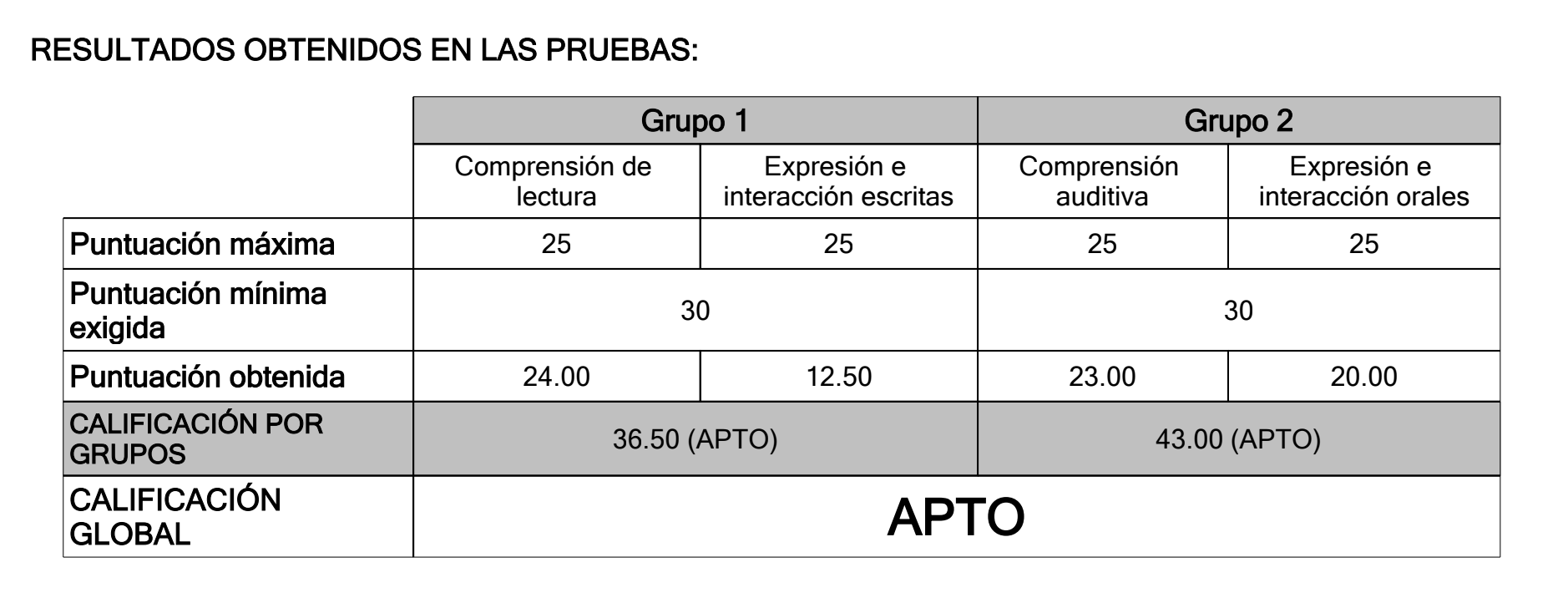
2023/11に試験を受けて結果が帰ってきたのが2024/02。せっかくなので貼っておくぜ。また1年後にモチベーションがあれば次のレベルを受けようかな~。